Hadoop
Hadoop是一个由Apache基金会所开发的分布式系统基础架构
Hadoop通常是指一个更广泛的概念——Hadoop生态圈.
三大发行版本:
- Apaache:基础版本
- CDH
- CDP
高可靠 高扩展 高效 高容错
发展历史
Lucene -> Nutch -> Haddop
组成
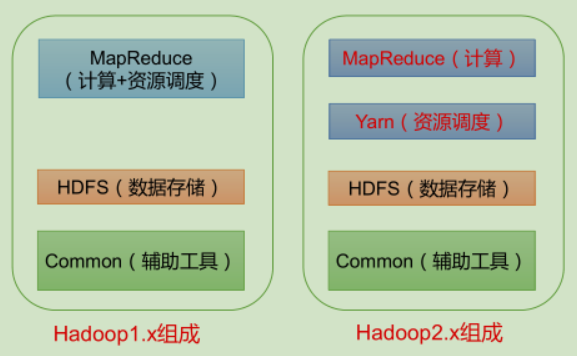
HDFS
- NameNode(nn):存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在的DataNode等,负责执行有关 文件系统命名空间 的操作,例如打开,关闭、重命名文件和目录等
- DataNode(dn):在本地文件系统存储文件块数据,以及块数据的校验和,负责提供来自文件系统客户端的读写请求,执行块的创建,删除等操作
- Secondary NameNode(2nn):每隔一段时间对NameNode元数据备份
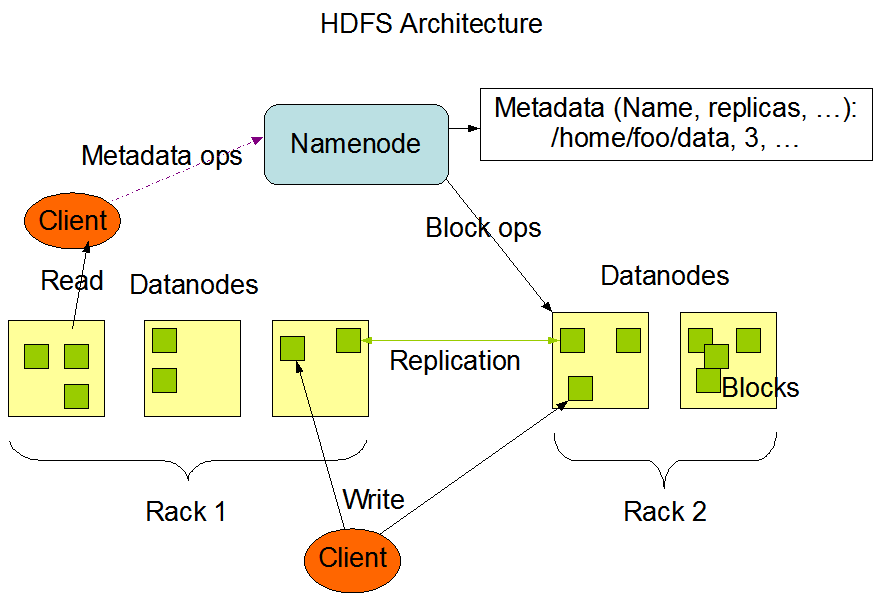
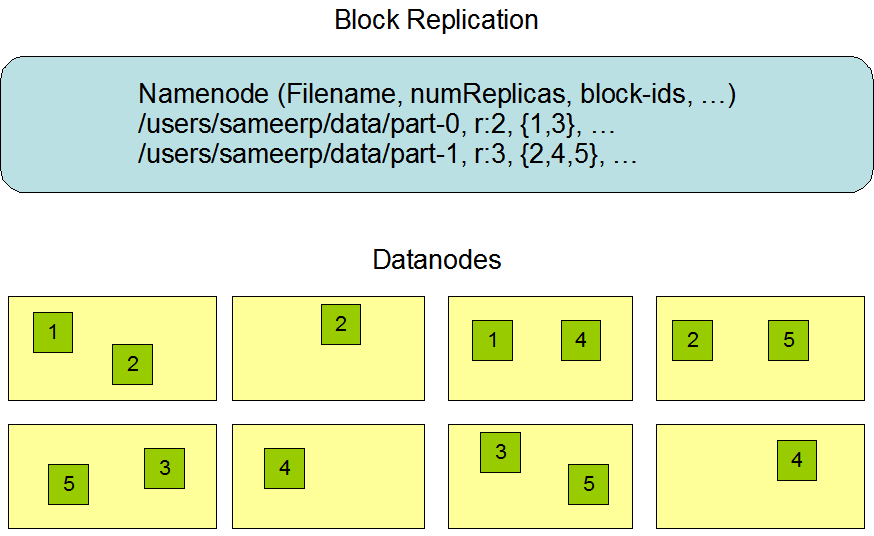
HDFS将文件分成一系列块,通过多副本分布在不同节点的方式来进行容错
HDFS的高可用设计:
- 数据存储故障容错:每块DataNode的数据都有校验和,如果读取时发现校验和对应不上,就到其他 DataNode 上读取备份数据
- 磁盘故障容错:如果 DataNode 监测到本机的某块磁盘损坏,则通知 NameNode 将对应的数据块复制到其他服务器上
- DataNode 故障容错:如果 NameNode 发现已经无法与某台 DataNode 联系,则必须将这台失联的 DataNode 的数据进行复制
- NameNode 高可用:利用 Zookeeper 进行选举,主从热备
GFS
GFS通过“命名空间 + 文件名”来定义一个文件,把每一个文件按照 64MB 一块的大小,切分成一个个 chunk。每个 chunk 都会有一个编号,能够唯一标识出具体的 chunk
每个 chunk 都会存上整整三份副本(replica)。其中一份是主数据(primary),两份是副数据(secondary),当三份数据出现不一致的时候,就以主数据为准,三份chunk存放在不同的chunkserver上面
当客户端需要读取文件时:根据文件名以及读取偏移量向Master确认chunk的位置后再自己去chunk读取数据
为了缓解单点读写的压力,Master将这些chunk元信息都存在内存中,通过定时的 Checkpoints 机制进行持久化,除了定时的 Checkpoints 机制,还会记录操作日志,恢复 = 快找 + 重放日志,等于 Redis 的 RDB + AOF,也就是复制状态机
为了避免 Master 挂掉影响可用性,GFS 通过引入一个影子 Master,这个影子Master不接受写请求,只是复制Master的数据,这样当主Master挂掉后,客户端还能从这个影子Master读取数据,但这也就意味着可能会存在短暂的数据不一致
sequenceDiagram
客户端 ->> Master: 获取要写入的数据所在的chunkserver
Master ->> 客户端: 返回chunkserver,并告知主数据所在的位置
客户端 ->> 主数据: 发送数据
主数据 ->> 副本A: 发送数据
副本A ->> 副本B: 发送数据
客户端 ->> 主数据: 可以写了
主数据 ->> 主数据: 内部排队
主数据 ->> 副本A: 可以写了
副本A ->> 主数据: OK
主数据 ->> 副本B: 可以写了
副本B ->> 主数据: OK
主数据 ->> 客户端: 写入完成
这种模式,控制流和数据流的分离,不仅仅是数据写入不需要通过 master,更重要的是实际的数据传输过程,和提供写入指令的动作是完全分离的,采用了流水线(pipeline)式的网络传输。数据不一定是先给到主副本,而是看网络上离哪个 chunkserver 近,就给哪个 chunkserver
GFS 专门为文件复制设计了一个 Snapshot 指令,当客户端通过这个指令进行文件复制的时候,这个指令会通过控制流,下达到主副本服务器,主副本服务器再把这个指令下达到次副本服务器,这样就实现了一份文件的复制
GFS 设计了一个专门的操作,叫做记录追加(Record Appends),当发生追加失败,主副本会告诉客户端数据写入失败,然后让客户端重试,这也就意味着大部分数据都是一致的,并且是确定的,但是整个文件中,会夹杂着少数不一致也不确定的数据
为了避免受错误数据的影响,客户端里面自带了对写入的数据去添加校验和,通过读取后进行校验,如果发生发现是错的,那就换个副本读取
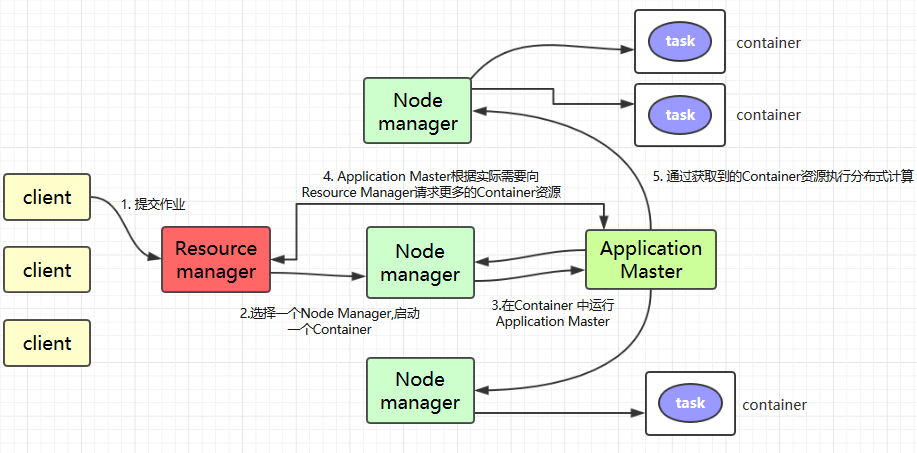
YARN
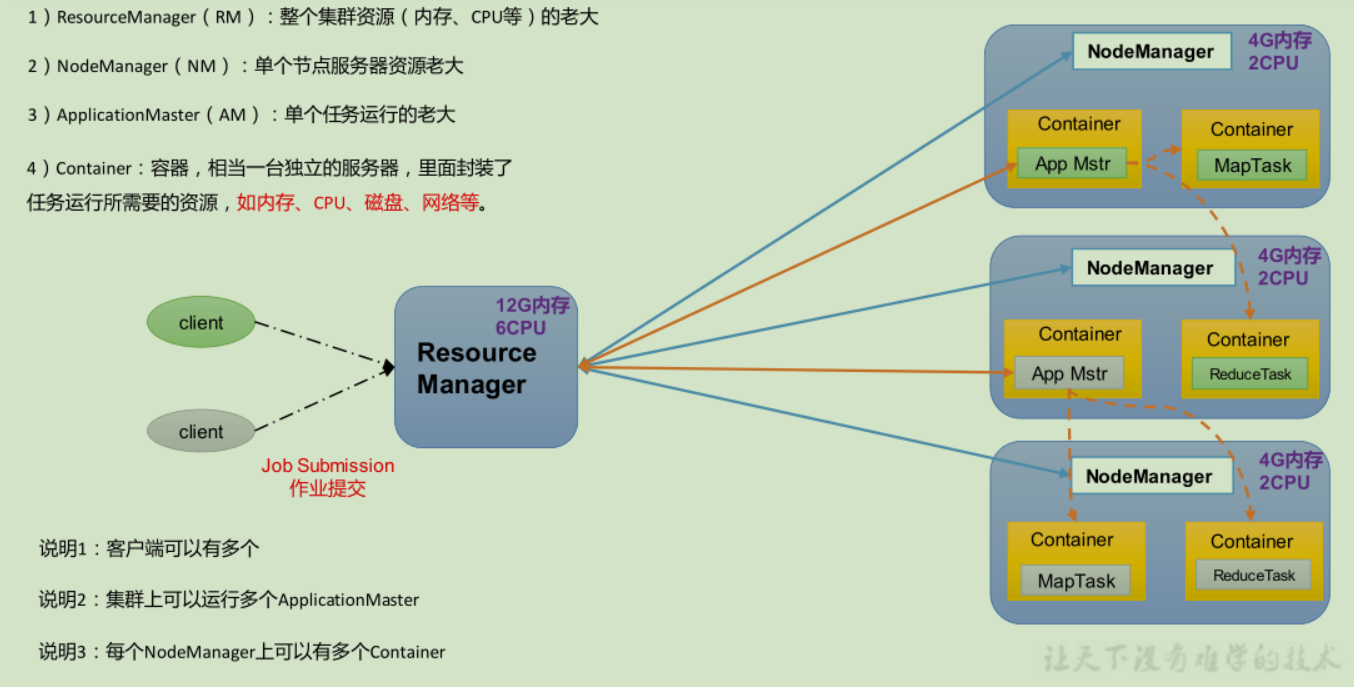
- ResourceManager: 在独立的机器上以后台进程的形式运行,负责给用户提交的所有应用程序分配资源, 根据规则制定分配策略,调度集群资源
- NodeManager:每个具体节点的管理者。主要负责该节点内所有容器的生命周期的管理,监视资源和跟踪节点健康
- ApplicationMaster:负责协调来自 ResourceManager 的资源,并通过 NodeManager 监视容器内资源的使用情况,同时还负责任务的监控与容错
- Container:YARN 中的资源抽象,它封装了某个节点上内存、CPU、磁盘、网络等资源,YARN 会为每个任务分配一个 Container
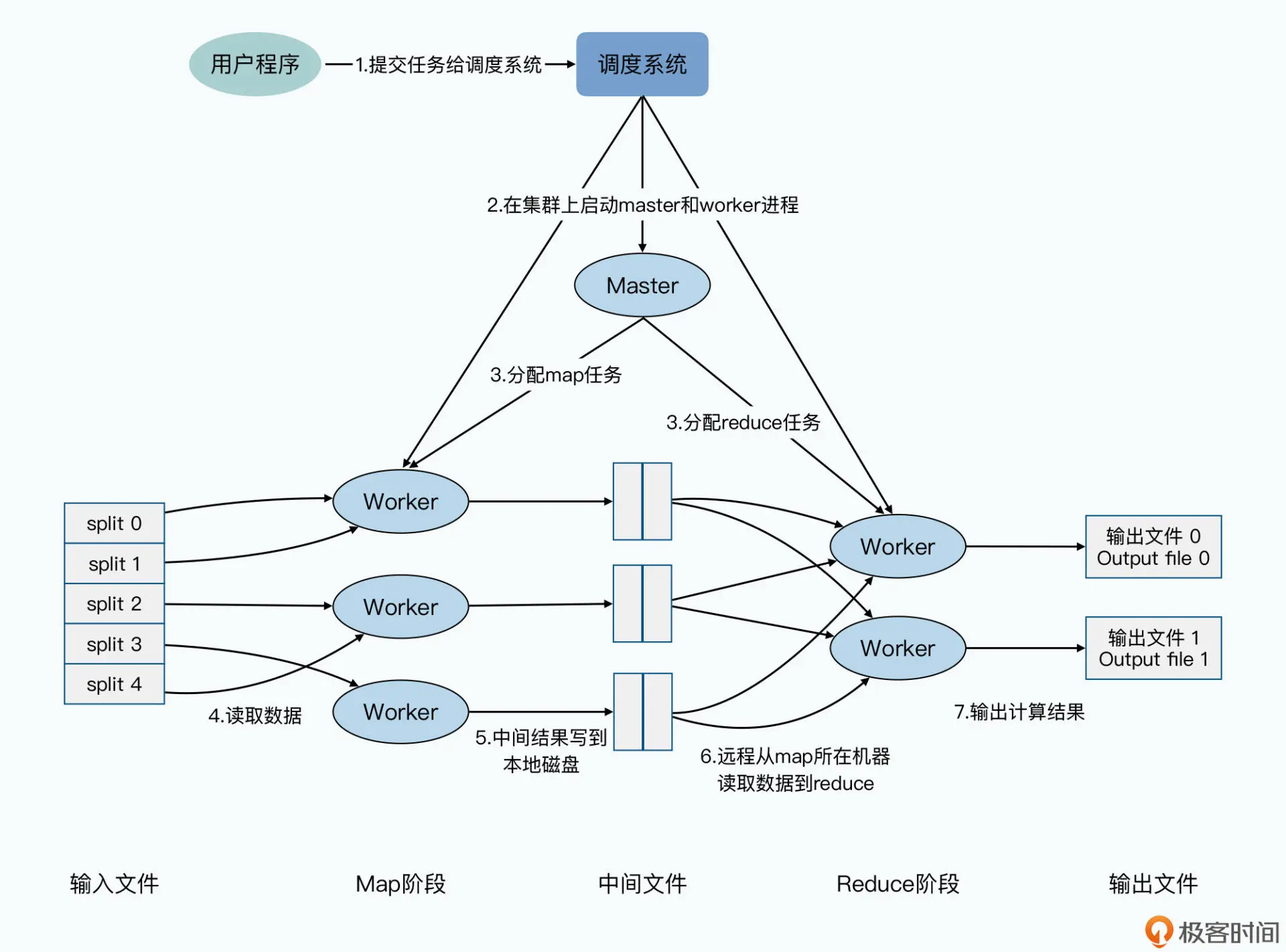
MapReduce
编程模型:
分任务 计算任务 汇总任务
// 接受一个 key-value 对,然后把这个 key-value 对转换成 0 到多个新的 key-value 对并输出出去
map (k1, v1) -> list (k2, v2)
// 接受一个 Key,以及这个 Key 下的一组 Value,然后化简成一组新的值 Value 输出出去
reduce (k2, list(v2)) -> list(v3)
shuffle:输出中间结果,输入中间结果的地方,也就是将不同服务器上map出来的相关数据合并到一起进行下一步的reduce计算
stateDiagram-v2
direction LR
HDFS输入文件目录 --> map任务1
map任务1 --> 中间结果1
HDFS输入文件目录 --> map任务2
map任务2 --> 中间结果2
HDFS输入文件目录 --> map任务3
map任务3 --> 中间结果3
中间结果1 --> reduce任务1
中间结果2 --> reduce任务1
中间结果3 --> reduce任务1
中间结果1 --> reduce任务2
中间结果2 --> reduce任务2
中间结果3 --> reduce任务2
中间结果1 --> reduce任务3
中间结果2 --> reduce任务3
中间结果3 --> reduce任务3
reduce任务1 --> HDFS输出文件目录
reduce任务2 --> HDFS输出文件目录
reduce任务3 --> HDFS输出文件目录
输出的结果:
- 搜索索引
- 键值对
这些map与reduce任务进程都是由一个master进程来控制
容错:
- 首先避免将任务分发到失效的进程上去,当某个任务进程中途崩溃,由于任务是无状态的,所以可以安全重试
- 周期性的把 master 相关的状态信息保存到磁盘中,形成一个个检查点。如果 master 任务失败了,我们就从最近的一个检查点恢复当时的执行状态,全部重新执行,这是一种比较简单的设计
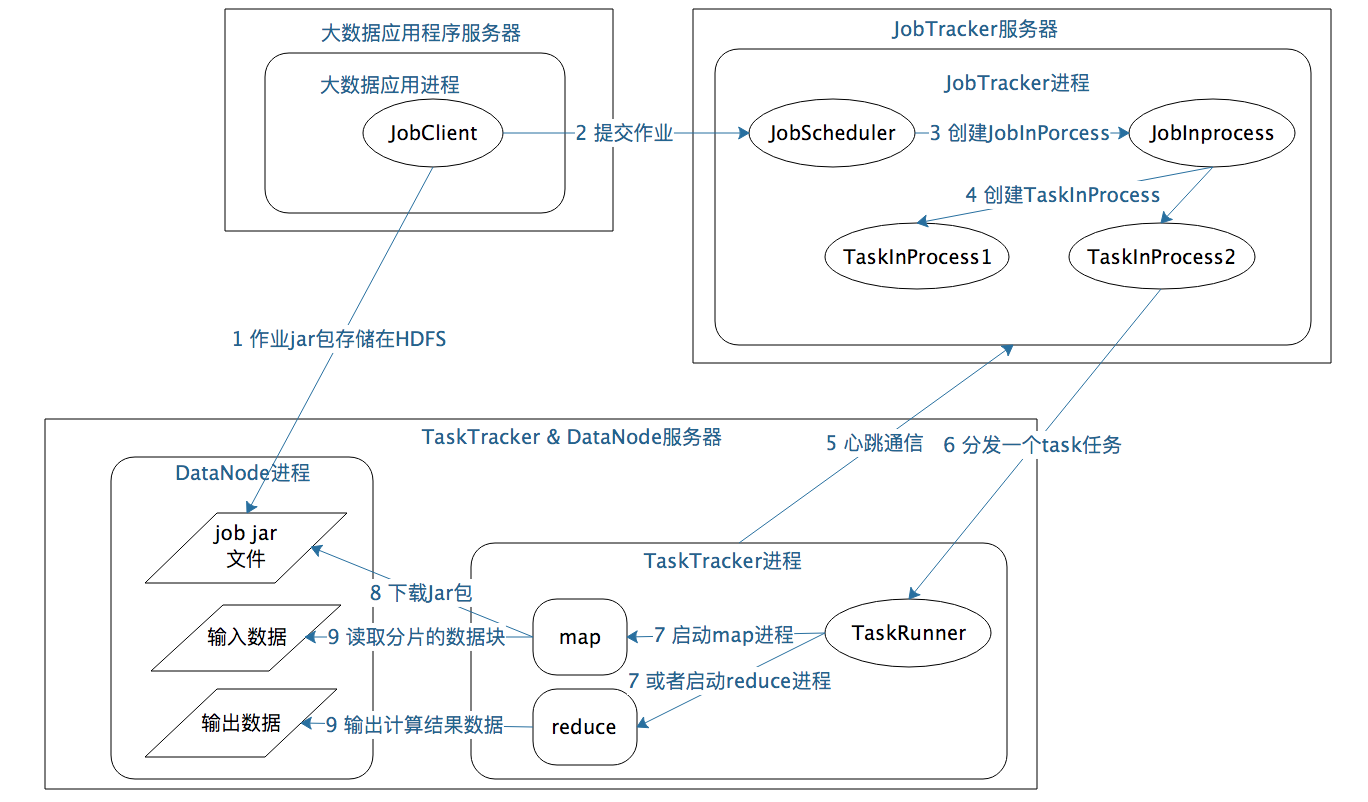
作业启动和运行机制:
- 大数据应用进程:启动 MapReduce 程序的主入口,主要是指定 Map 和 Reduce 类、输入输出文件路径等,并提交作业给 Hadoop 集群
- JobTracker 进程:根据要处理的输入数据量命令 TaskTracker 进程启动相应数量的 Map 和 Reduce 进程任务,并管理整个作业生命周期的任务调度和监控
- TaskTracker 进程:负责启动和管理 Map 进程以及 Reduce 进程,通常和 HDFS 的 DataNode 进程启动在同一个服务器
性能优化:
- 计算向存储移动:根据需要读取的数据,就近分配程序到离数据最近的worker
- 压缩输出:在map之后,进行Combiner 合并,减少在网络传输的数据
调试:
- 单机版的MapReduce进行小数据量的测试
- 使用内部监控机制提升可观测性
安装
https://github.com/big-data-europe/docker-hadoop
测试集群:
adoop fs -mkdir /test # 创建文件夹