爬虫
网络爬虫,是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
爬虫分类
- 通用
- 聚焦
- 增量式
- 深层网络
网页去重
- simhash
海明距离
在信息编码中,两个合法代码对应位上编码不同的位数称为码距,又称海明距离。举例如下:10101和00110从第一位开始依次有第一位、第四、第五位不同,则海明距离为3
运行方式
- 起始爬行页面集合:通过手动指定或者自动化的方式,是爬虫的种子列表
- 从起始爬行页面提取链接,对链接规范化,处理掉链接的别名(如url里的hash),并将相对链接转为绝对链接,加入爬行列表
- 减少爬取环路,使用哈希表、布隆过滤器等过滤爬取过的页面,并且要将这些数据持久化
- 由于诸如CGI以及文件系统的符号链接等的存在,环路是无法完全避免的
环路减少策略
- 规范化URL 避免别名
- 广度优先爬行,避免无限深入某一URL链
- 对每个站点进行流量控制,避免爬取的太多
- 限制URL的长度
- 人工监视,维护URL环路黑名单
- 对URL进行模式检测,发现可能是回环的URL
- 内容指纹,对内容进行取数字摘要
robots.txt
| 版本 | 说明 |
|---|---|
| 0.0 | 支持Disallow指令 禁止爬行 |
| 1.0 | 支持Allow指令 允许爬行 |
| 2.0 | 新增正则表达式及定时功能 |
格式
# 注释: 禁止百度蜘蛛和谷歌蜘蛛爬取/admin
User-Agent: baidu-spider
User-Agent: google-spider
Disallow: /admin
# 禁止所有蜘蛛爬取/super-admin
User-Agent: *
Disallow: /super-admin
url的匹配是前缀匹配
爬虫META指令
<meta name='robots' content='noindex'>
content可取值如下:
- noindex 禁止索引本页面
- nofollow 禁止爬取本页面的外链
- index 可以对本页面索引
- follow 可以爬取本页面的所有外链
- all 等价于 index+follow
- none 等价于 noindex+nofollow
给搜索引擎的META标签
<meta name='description' content="页面描述">
<meta name='keywords' content="关键词1, 关键词2">
<!-- 10天后再来爬一次 -->
<meta name='revisit-after' content="10 days">
使用Java爬
HttpClient
Get请求
HttpGet get = new HttpGet("http://www.baidu.com");
try (CloseableHttpClient client = HttpClients.createDefault();
CloseableHttpResponse response = client.execute(get)) {
String s = EntityUtils.toString(response.getEntity(), "utf8");
System.out.println(s);
}
- 设置参数
URIBuilder uriBuilder = new URIBuilder("http://www.baidu.com/s").addParameter("wd", "关键词");
HttpGet get = new HttpGet(uriBuilder.build());
POST请求
var request = new HttpPost("http://example");
var pairs = List.of(new BasicNameValuePair("keys", "java"), new BasicNameValuePair("keys", "python"));
UrlEncodedFormEntity entity = new UrlEncodedFormEntity(pairs, "utf8");
request.setEntity(entity);
连接池
PoolingHttpClientConnectionManager manager = new PoolingHttpClientConnectionManager();
// 最大连接数
manager.setMaxTotal(100);
// 每个主机最大连接数
manager.setDefaultMaxPerRoute(10);
CloseableHttpClient client = HttpClients.custom().setConnectionManager(manager).build();
请求参数
RequestConfig config = RequestConfig.custom().setConnectTimeout(1000) // 获取连接的最长时间,单位ms
.setConnectionRequestTimeout(500) // 获取连接的最长时间
.setSocketTimeout(10000).build(); // 传输数据最长时间
HttpGet get = new HttpGet();
get.setConfig(config);
Jsoup
DOM
Document doc = Jsoup.parse(new URL("http://www.baidu.com"), 10000);
doc.getElementByXXX();
元素API
Element e = doc.getElementById("login");
System.out.println(e.id());
System.out.println(e.className());
System.out.println(e.classNames());
System.out.println(e.text());
System.out.println(e.attr("style"));
System.out.println(e.attributes());
使用CSS选择器
doc.select("div")
.forEach(System.out::println);
WebMagic
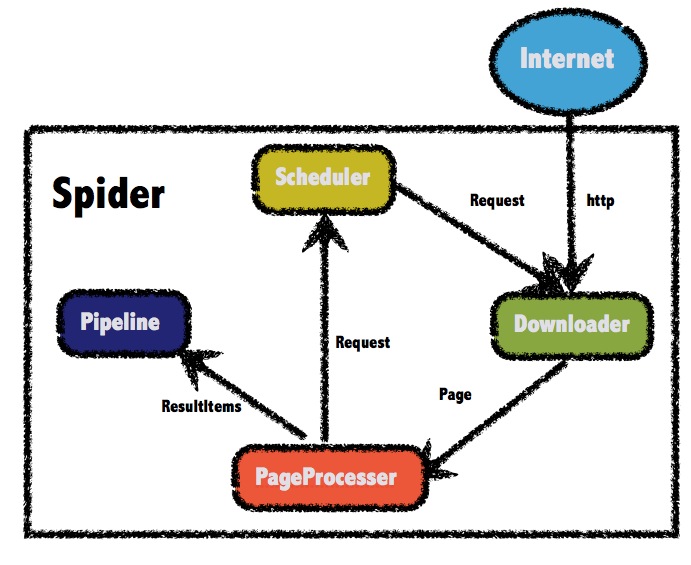
使用
- 实现PageProcessor
public class JobProcessor implements PageProcessor {
private Site site = Site.me().addHeader("User-Agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36");
@Override
public void process(Page page) {
page.putField("div1",page.getHtml().css("#logo-2014").get());
page.putField("div2",page.getHtml().xpath("//div").get());
}
@Override
public Site getSite() {
return site;
}
}
- 运行
Spider.create(new JobProcessor())
.addUrl("https://search.jd.com/Search?keyword=%E6%89%8B%E6%9C%BA&enc=utf-8&wq=%E6%89%8B%E6%9C%BA&pvid=9524dc8e0e2d45f08656f023fa60a0de")
.run();
元素抽取
- XPath
- Regex
- CSS
page.putField("div1",page.getHtml().css("#logo-2014").get()); // 获取一条
page.putField("div2",page.getHtml().xpath("//div[@id=logo-2014]").all()); // 获取全部
获取链接
page.getHtml().links()
- 递归访问
page.addTargetRequests(page.getHtml().links().all());
输出数据
- PipeLine
Spider.create(new JobProcessor())
.addUrl("url")
.addPipeline(new FilePipeline("./result.txt"))
.run();
Site
Scheduler
- 使用布隆过滤器
Spider.create(null)
.setScheduler(new QueueScheduler().setDuplicateRemover(new BloomFilterDuplicateRemover(100000)));
三种去重方式
- HashSet
- Redis
- 布隆过滤器
文档
使用代理
downloader.setProxyProvider(new SimpleProxyProvider(List.of(new Proxy("116.114.19.211",443))));
Spider.create(new ProxyProcessor())
.addUrl("http://ip-api.com/json/?lang=zh-CN")
.setDownloader(downloader)
.run();